Python爬虫之scrapy框架
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
安装及介绍
安装
通过cmd命令执行 pip install scrapy即可安装。
注意:
在ubuntu 上安装scrapy之前,需要先安装以下依赖:
sudo apt-It install python-dev python-pip libxml2-dev libxslt1-dev zliblg-dev libffi-dev libssl-dev ,然后再通过pip install scrapy 安装。
如果在windows 系统下运行时,提示这个错误ModuleNotFoundError: No module named ‘win32api’ ,那么使用以下命令可以解决: pip install pypiwin32 ,一般做法,就提前执行这个命令
文档
介绍
Scrapy架构图如图所示: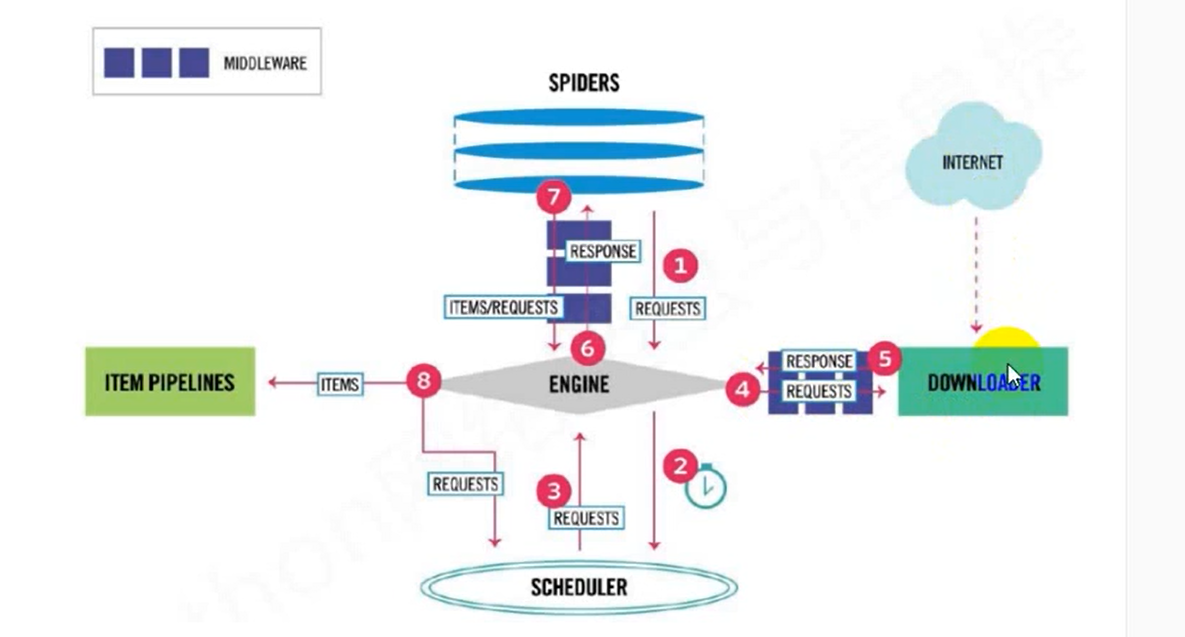
Scrapy架构
- Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
项目创建
- 创建项目:cmd命令进入你要创建项目的目录下,执行命令:
scrapy startproject [项目名字]
- 创建爬虫:进入项目所在的路径,执行命令:
scrapy genspider [爬虫名字] [爬虫的域名]
注意:爬虫名字不能和项目名字一致。
- 生成目录如下:
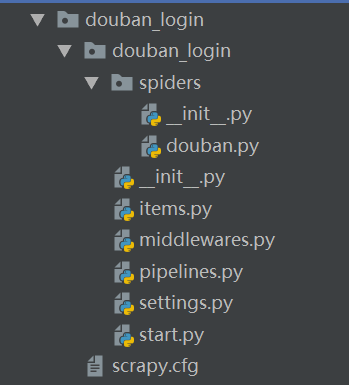
- items.py: 用来存放爬虫爬取下来数据的模型。eg:content = scrapy.Field()
- middlewares.py: 用来存放各种中间件的文件.下载器中间件可以用来设置代理ip、user-agent来反反爬虫,需要在配置文件里配置SPIDER_MIDDLEWARES,不然就不会启动中间件。
- pipelines.py:用来将items的模型 存储到本地磁盘中。里面存放pipline类,类中包括有init函数(用来打开存储数据的文件,例如json文件,或者连接数据库)、open_spider()(和init函数一样,但一般使用init函数)、process_item()(写入数据到文件中、或者执行数据库插入命令)、close_spider()(关闭文件).也是要去setting.py文件中取消ITEM_PIPELINES 注释,你要使用哪个pipline类就取消哪一个的注释,也可以在后面设置优先级。
- settings.py: 本爬虫的一些配置信息(比如请求头、是否遵从机器人协议、下载延迟等)。
- scrapy.cfg: 项目的配置文件。
- spiders包: 以后所有的爬虫,都是存放到这个里面。做解析页面的操作,最后yeild返回 items数据。
Scrapy shell终端
Scrapy shell是一个交互式终端,可以用来检测你用XPatn或者CSS表达式解析网页是否错误。避免了每次修改都要运行一次爬虫。
用法
在cmd终端执行如下命令:
1 | scrapy shell [url] |
[url]即你打算解析的网页的网址
然后输入你的XPath表达式,判断结果是否真确。
实战
糗事百科Scrapy爬虫笔记:
- response是一个‘scrapy. http.response.html.HtmlResponse’对象。可以执行‘xpath’和‘css’语法来提取数据。
2.提取出来的数据,是一个‘Selector’ 或者是一个‘SelectorList’对象。如果想要获取其中的字符串。那么应该执行‘getall()’或者‘get()’方法。
getall方法:获取‘Selector’中的所有文本。返回的是一一个列表。
get方法:获取的是‘Selector’中的第 一个文本。返回的是一个str类型。
5.如果数据解析回来,要传给pipline处理。那么可以使用yield来返回。或者是收集所有的item,最后统一使用return返回。
item: 建议在‘items.py’中定义好模型。以后就不要使用字典。
pipeline: 这个是专门用来保存数据的。其中有三个方法是会经常用的。
- open spider(self,spider): 当爬虫被打开的时候执行。
- process_ item(self, item, spider): 当爬虫有item传过来的时候会被调用。
- close_ spider(self, spider): 当爬虫关闭的时候会被调用。
要激活piplilne,应该在settings.py中,设置ITEM PIPELINES。
JsonItemExporter和JsonLinesItemExporter
保存json数据的时候,可以使用这两个类,让操作变得得更简单。
1.、JsonItemExporter:这个是每次把数据添加到内存中。最后统一写入到磁盘中。好处是,存储的数据是一个满足json规则的数据。坏处是如果数据量比较大,那么比较耗内存。
2.、JsonL inesItemExporter:这个是每次调用export_ item的时候就把这个item存储到硬盘中。坏处是每一个字典是一行,整个文件不是一个满足json格式的文件。好处是每次处理数据的时候就直接存储到了硬盘中,这样不会耗内存,数据也比较安全。

