网络爬虫之数据提取
数据提取的解析器有lxml、Beautifulsoup和正则表达式三种,对比如下:
| 解析工具 | 解析速度 | 使用难度 |
|---|---|---|
| lxml | 快 | 简单 |
| BeautifulSoup | 最慢 | 最简单 |
| 正则表达式 | 最快 | 最难 |
Xpath
xpath (XML Path Language)是- -门 ]在XML和HTML文档中查找信息的语信,可用来在XML和HTML文档中对元素和属性进行遍历。
XPath开发工具
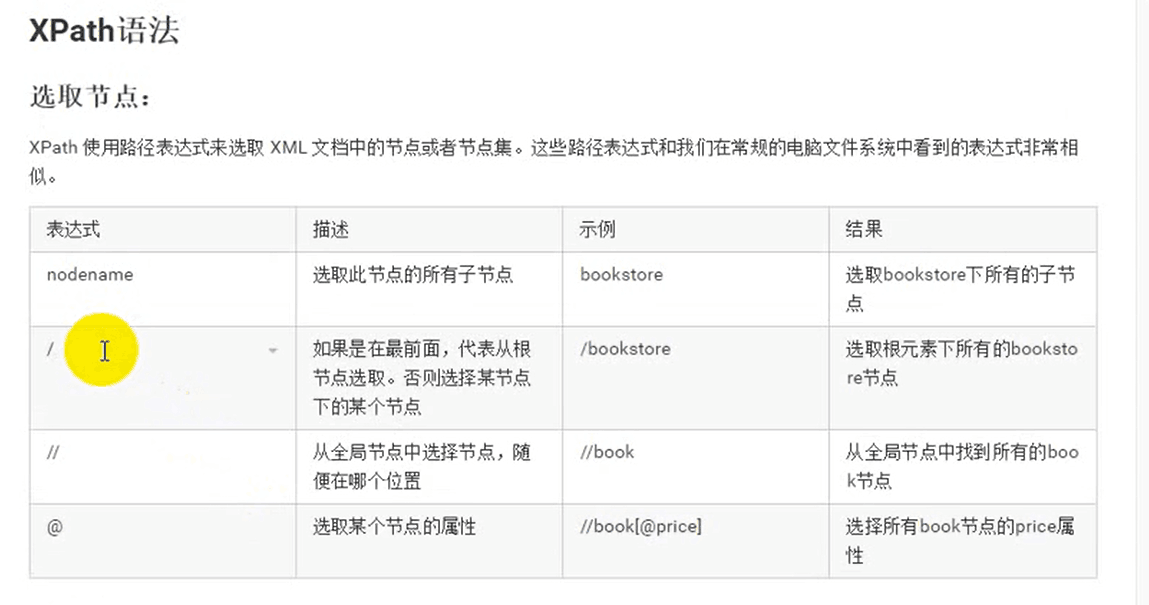

使用方式:
使用//获取整个页面当中的元素,然后写标签名,然后再写谓词进行提取。比如:1
//div[@class='abc']
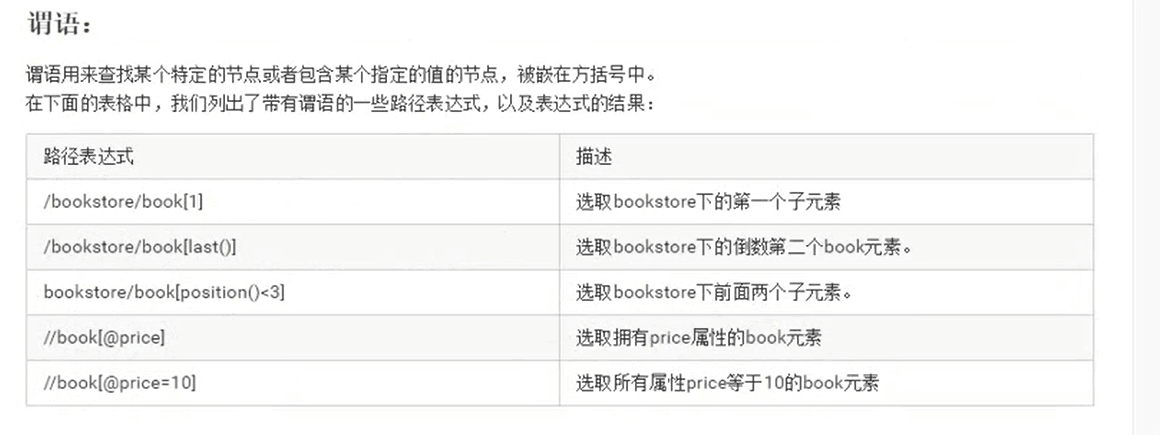
需要注意的知识点:
- /和//的区别:/代表只获取直接子节点。//获取子孙节点。一般//用得比较多。当然也要视情况而定。
contains:有时候某个属性中包含了多个值,那么可以使用
contains函数。示例代码如下:1
//div[contains(@class,'job_detail')]
谓词中的下标是从1开始的,不是从0开始的。
lxml解析器解析HTML代码
安装lxml
1 | pip install lxml |
使用
解析html字符串:使用
lxml.etree.HTML进行解析。示例代码如下:1
2
3
4from lxml import etree
htmlElement = etree.HTML(text)
print(etree.tostring(htmlElement,encoding='utf-8').decode("utf-8"))解析html文件:使用
lxml.etree.parse进行解析。示例代码如下:1
2htmlElement = etree.parse("tencent.html")
print(etree.tostring(htmlElement, encoding='utf-8').decode('utf-8'))这个函数默认使用的是XML解析器,所以如果碰到一些不规范的HTML代码的时候就会解析错误,这时候就要自己创建HTML解析器。
1
2
3parser = etree.HTMLParser(encoding='utf-8')
htmlElement = etree.parse("lagou.html",parser=parser)
print(etree.tostring(htmlElement, encoding='utf-8').decode('utf-8'))
lxml结合xpath
- 使用
xpath语法。应该使用Element.xpath方法。来执行xpath的选择。示例代码如下:1
trs = html.xpath("//tr[position()>1]")
xpath函数返回来的永远是一个列表。
获取某个标签的属性:
1
2href = html.xpath("//a/@href")
# 获取a标签的href属性对应的值获取文本,是通过
xpath中的text()函数。示例代码如下:1
address = tr.xpath("./td[4]/text()")[0]
在某个标签下,再执行xpath函数,获取这个标签下的子孙元素,那么应该在斜杠之前加一个点,代表是在当前元素下获取。示例代码如下:
1
address = tr.xpath("./td[4]/text()")[0]
综合示例如下:
1 | #encoding: utf-8 |
- 下面是两个实战例子,爬取豆瓣电影top250网页内容和爬取电影天堂近期电影网页内容,已上传到码云,地址如下。
BeautifulSoup
安装
1 | pip install bs4 |
用BeautifulSoup解析的时候需要指定一些解析器,一些常用的解析器: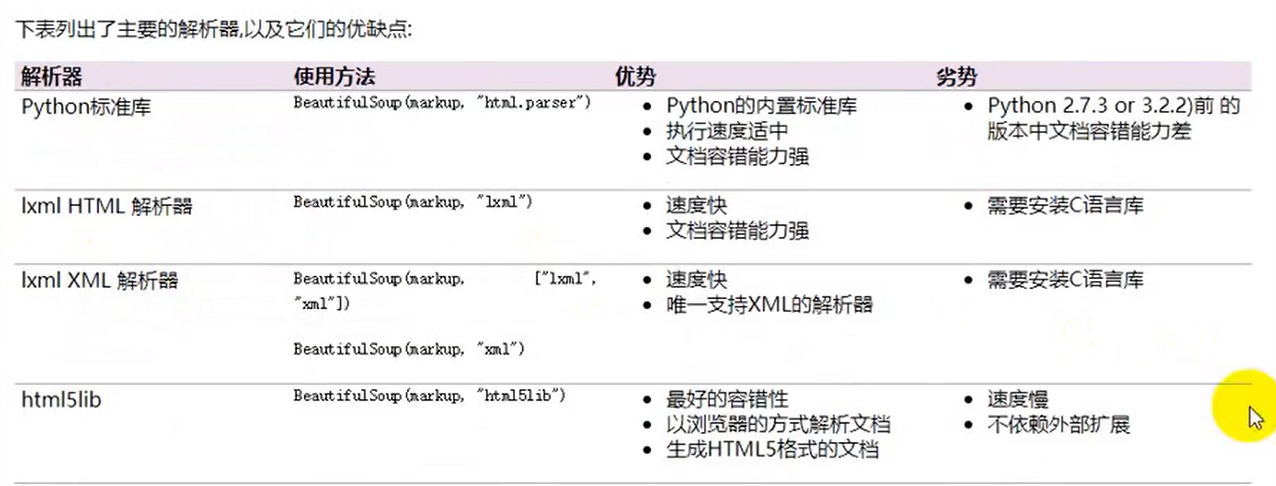
各种解析器的优势和劣势在图中可以很明显看出,这里多说一句:html5lib是一个类似浏览器的解析器,功能很强大,如果遇到那些很古怪的网页代码就可以考虑用这个解析器,直接用命令:pip install html5lib 安装即可。
使用
1 | #encoding: utf-8 |
find_all与find
find_all的使用:
- 在提取标签的时候,第一个参数是标签的名字。然后如果在提取标签的时候想要使用标签属性进行过滤,那么可以在这个方法中通过关键字参数的形式,将属性的名字以及对应的值传进去。或者是使用
attrs属性,将所有的属性以及对应的值放在一个字典中传给attrs属性。 - 有些时候,在提取标签的时候,不想提取那么多,那么可以使用
limit参数。限制提取多少个。
find与find_all的区别:
- find:找到第一个满足条件的标签就返回。说白了,就是只会返回一个元素。
- find_all:将所有满足条件的标签都返回。说白了,会返回很多标签(以列表的形式)。
使用find和find_all的过滤条件:
- 关键字参数:将属性的名字作为关键字参数的名字,以及属性的值作为关键字参数的值进行过滤。
- attrs参数:将属性条件放到一个字典中,传给attrs参数。
获取标签的属性:
通过下标获取:通过标签的下标的方式。
1
href = a['href']
通过attrs属性获取:示例代码:
1
href = a.attrs['href']
string和strings、stripped_strings属性以及get_text方法:
- string:获取某个标签下的非标签字符串(他自己的)。返回来的是个字符串。如果这个标签下有多行字符,那么就不能获取到了。
- strings:获取某个标签下的子孙非标签字符串。返回来的是个生成器。
- stripped_strings:获取某个标签下的子孙非标签字符串,会去掉空白字符。返回来的是个生成器。
- get_text:获取某个标签下的子孙非标签字符串。不是以列表的形式返回,是以普通字符串返回。
综合示例
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73#encoding: utf-8
from bs4 import BeautifulSoup
html = """省略 """
soup = BeautifulSoup(html,'lxml')
# 1. 获取所有tr标签
trs = soup.find_all('tr')
for tr in trs:
print(tr)
print('='*30)
# 2. 获取第2个tr标签
tr = soup.find_all('tr',limit=2)[1]第二个参数limit用来限制获取的数量,防止太多
print(tr)
# 3. 获取所有class等于even的tr标签
trs = soup.find_all('tr', class_ = "even")
# trs = soup.find_all('tr',attrs={'class':"even"})# atrribute属性
for tr in trs:
print(tr)
print('='*30)
# 4. 将所有id等于test,class也等于test的a标签提取出来。
# aList = soup.find_all('a',id='test',class_='test')
aList = soup.find_all('a',attrs={"id":"test","class":"test"})
for a in aList:
print(a)
# 5. 获取所有a标签的href属性
aList = soup.find_all('a')
for a in aList:
# 1. 通过下标操作的方式
# href = a['href']
# print(href)
# 2. 通过attrs属性的方式
href = a.attrs['href']
print(href)
# 6. 获取所有的职位信息(纯文本)
trs = soup.find_all('tr')[1:] #第0个tr标签不需要
movies = []
for tr in trs:
movie = {}
# 方式1
# tds = tr.find_all("td")
# title = tds[0].string # 去掉多余的标签
# category = tds[1].string
# nums = tds[2].string
# city = tds[3].string
# pubtime = tds[4].string
# movie['title'] = title
# movie['category'] = category
# movie['nums'] = nums
# movie['city'] = city
# movie['pubtime'] = pubtime
# movies.append(movie)
# 方式2
#2.1
infos = list(tr.strings) #这种方法换行符等空白字符也会被提取出来
print(infos)
#2.2
infos = list(tr.stripped_strings)#stripp可以过滤空白字符
movie['title'] = infos[0]
movie['category'] = infos[1]
movie['nums'] = infos[2]
movie['city'] = infos[3]
movie['pubtime'] = infos[4]
movies.append(movie)
print(movies)
有关匿名函数(lambda表达式)和map函数的用法。
map函数
lambda表达式
正则表达式
匹配规则
特殊匹配字符
- 匹配一个字符
- ‘字符串’:匹配某个字符串。
- 点:匹配任意的字符。但是不能匹配\n,可以添加参数:re.DOTALL解决
- \d:匹配任意的数字(0-9)。
- \D:匹配任意的非数字。
- \s:匹配空白字符(\n,\t,\r,空格)\r回车。
- \w:匹配的是a-z,A-Z,数字和下划线。
- \W:与\w相反。
- []组合的方式,只要满足中括号中的字符,就可以匹配, 中括号的形式代替\d:[0-9];中括号的形式代替\D:[^0-9];中括号的形式代替\w:[a-zA-Z0-9_];中括号的形式代替\W:[^a-zA-Z0-9_]
- 匹配多个字符
- *:可以匹配0或者任意多个字符
- +:匹配1个或者多个字符 , 如果第一个不是,就返回错误
- ?:匹配一个或者0个(要么没有,要么就只有一个)
- {m}:匹配m个字符。
- {m,n}:匹配m-n个字符 ,匹配到最多的字符(不超过n)返回
- 小案例
3.1. 验证手机号码:
1 | text = "12578900980" # 以1开头,第二位是34578中的一位,后面九个字符任意 |
3.2. 验证邮箱:
1 | text = "hynever12_@163com" |
3.3. 验证URL
1 | text = "https://baike.baidu.com/item/Python/407313?fr=aladdin" |
3.4. 验证身份证:
1 | text = "31131118908123230a" |
- 特殊字符
- ^(脱字号): # 表示以…开始,match函数本身就从第一个开始匹配,匹配不成功就返回错误,所以不需要脱字符
- $:表示以…结尾:将正常字符(非正则表达式特殊字符)规定到结尾的规则中来
- |:匹配多个字符串或者表达式中的一个。
- 贪婪模式与非贪婪模式:贪婪模式匹配最长的满足条件的字符,非贪婪模式在后面加个?就只匹配满足条件的最短的结果
举例:
4.1.1
2
3text = "<h1>标题</h1>"
ret = re.match('<.+?>',text) #没有?匹配到<h1>标题</h1>,有?匹配到<h1>
print(ret.group())
4.2. 匹配0-100之间的数字, 即不可以出现类似:09,101 10011
2
3text = "01"
ret = re.match('[1-9]\d?$|100$',text)
print(ret.group())
- 转移字符和原生字符串
1 | #encoding: utf-8 |
匹配函数
match 和 search 函数
- match:从开始的位置进行匹配。如果开始的位置没有匹配到。就直接失败了。如果想要匹配空白字符的数据,那么就要传入一个flag=re.DOTALL ,就可以匹配换行符了。(re.S=re.DOTALL)示例代码如下:
1 | import re |
- search:在字符串中找满足条件的字符。如果找到,就返回。说白了,就是只会找到第一个满足条件的。
group分组
在正则表达式中,可以对过滤到的字符串进行分组。分组使用圆括号的方式。
- group :和group(e)是等价的,返回的是整个满足条件的字符串。
- groups :返回的是里面的子组。索引从1开始。
- group(1) :返回的是第一 个子组,可以传入多个。示例代码如下:
1 |
|
re模块常用函数
- findall函数:找出所有满足条件的,返回的是一个列表。
1 | text = "apple's price $99,orange's price is $10" |
- sub函数:用来替换字符串,将匹配到字符串替换为其他字符。
1 | text = "apple's price $99,orange's price is $10" |
sub函数可以用作替换html标签,提取文本信息,例如拉勾网的职位招聘信息。1
ret = re.sub('<.+?>',"",html) # ?非贪婪模式
- split函数:使用正则表达式来分割字符串。
1 | text = "hello&world ni hao" |
- compile函数:对于一些经常要用到的正则表达式,可以使用compile 进行编译,后期再使用的时候可以直接拿过来用,执行效率会更快。而且compile 还可以指定flag=re.VERBOSE,在写正则表达式的时候可以做好注释。
1 | text = "the number is 20.50" |

