巩固python基础
ps: 该篇博客学习自菜鸟教程
中文编码
Python中默认的编码格式是 ASCII 格式,在没修改编码格式时无法正确打印汉字,所以在读取中文时会报错。
解决方法为只要在文件开头加入 # -*- coding: UTF-8 -*- 或者 #coding=utf-8 就行了
注意:**#coding=utf-8 的 =** 号两边不要空格。
标识符
以下划线开头的标识符是有特殊意义的。以单下划线开头 _foo 的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用 from xxx import * 而导入。
以双下划线开头的 __foo 代表类的私有成员,以双下划线开头和结尾的 foo 代表 Python 里特殊方法专用的标识,如 init() 代表类的构造函数。
行和缩进
学习 Python 与其他语言最大的区别就是,Python 的代码块不使用大括号 {} 来控制类,函数以及其他逻辑判断。python 最具特色的就是用缩进来写模块。
缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。多行语句
Python语句中一般以新行作为语句的结束符。
但是我们可以使用斜杠( \)将一行的语句分为多行显示,如下所示:1
2
3total = item_one + \
item_two + \
item_three
语句中包含 [], {} 或 () 括号就不需要使用多行连接符。
Print 输出
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上逗号 ,
1 | # -*- coding: UTF-8 -*- |
以上实例执行结果为:
a
b
a b a b
标准数据类型
Python有五个标准的数据类型:
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
数字
- 长整型也可以使用小写 l,但是还是建议您使用大写 L,避免与数字 1 混淆。Python使用 L 来显示长整型。
Python 还支持复数,复数由实数部分和虚数部分构成,可以用 a + bj,或者 complex(a,b) 表示, 复数的实部 a 和虚部 b 都是浮点型。
注意:long 类型只存在于 Python2.X 版本中,在 2.2 以后的版本中,int 类型数据溢出后会自动转为long类型。在 Python3.X 版本中 long 类型被移除,使用 int 替代。字符串
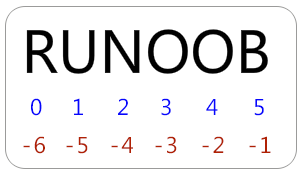
python的字串列表有2种取值顺序:
从左到右索引默认0开始的,最大范围是字符串长度少1
- 从右到左索引默认-1开始的,最大范围是字符串开头
实例
1
2
3
4
5
6
7
8
9
10# -*- coding: UTF-8 -*-
str = 'Hello World!'
print str # 输出完整字符串
print str[0] # 输出字符串中的第一个字符
print str[2:5] # 输出字符串中第三个至第五个之间的字符串
print str[2:] # 输出从第三个字符开始的字符串
print str * 2 # 输出字符串两次
print str + "TEST" # 输出连接的字符串
以上实例输出结果:
Hello World!
H
llo
llo World!
Hello World!Hello World!
Hello World!TEST
- Python 列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串:
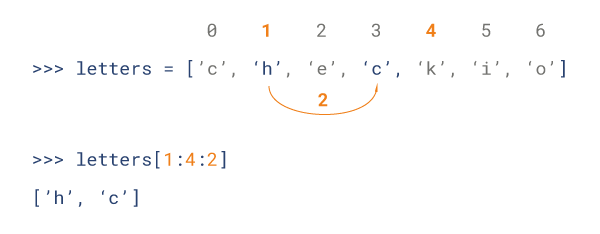
列表
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
列表用 [ ] 标识,是 python 最通用的复合数据类型。
列表方法
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False) 对原列表进行排序 |
实例
1 | # -*- coding: UTF-8 -*- |
以上实例输出结果如下:
降序输出: [‘u’, ‘o’, ‘i’, ‘e’, ‘a’]
元组
元组是另一个数据类型,类似于 List(列表)。
元组用 , 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
创建空元组
tup1 = ()
元组中只包含一个元素时,需要在元素后面添加逗号
tup1 = (50,)
实例
1 | # -*- coding: UTF-8 -*- |
以上实例输出结果:
(‘runoob’, 786, 2.23, ‘john’, 70.2)
runoob
(786, 2.23)
(2.23, ‘john’, 70.2)
(123, ‘john’, 123, ‘john’)
(‘runoob’, 786, 2.23, ‘john’, 70.2, 123, ‘john’)
字典
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典用”{ }”标识。字典由索引(key)和它对应的值value组成。
删除字典元素
####### 实例1
2
3
4
5
6# -*- coding: UTF-8 -*-
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
del dict['Name'] # 删除键是'Name'的条目
dict.clear() # 清空词典所有条目
del dict # 删除词典
内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys(seq[, val]) 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
| 5 | dict.has_key(key) 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | dict.keys() 以列表返回一个字典所有的键 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新添加到dict里 |
| 10 | dict.values() 以列表返回字典中的所有值 |
| 11 | pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 随机返回并删除字典中的一对键和值。 |
####### 实例
以下实例展示了 fromkeys()函数的使用方法:
1 | # -*- coding: UTF-8 -*- |
以上实例输出结果为:
新字典为 : {‘Google’: None, ‘Taobao’: None, ‘Runoob’: None}
新字典为 : {‘Google’: 10, ‘Taobao’: 10, ‘Runoob’: 10}
实例
1 | # -*- coding: UTF-8 -*- |
输出结果为:
This is one
This is two
{‘dept’: ‘sales’, ‘code’: 6734, ‘name’: ‘john’}
[‘dept’, ‘code’, ‘name’]
[‘sales’, 6734, ‘john’]
运算符
算数运算符
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果 100000000000000000000 |
|---|---|---|
| // | 取整除 - 返回商的整数部分(向下取整) | >>> 9//2 4 >>> -9//2 -5 |
位运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1 。~x 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011,在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把”>>”左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔”与” - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔”或” - 如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔”非” - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
成员运算符
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个, == 用于判断引用变量的值是否相等。
字符串运算符
| 运算符 | 描述 | |
|---|---|---|
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母”r”(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | >>>print r’\n’ \n >>> print R’\n’ \n |
运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 ‘AND’ |
| ^ \ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
语句
- python 并不支持 switch 语句,所以多个条件判断,只能用 elif 来实现,如果判断需要多个条件需同时判断时,可以使用 or (或),表示两个条件有一个成立时判断条件成功;使用 and (与)时,表示只有两个条件同时成立的情况下,判断条件才成功。
pass 语句
Python pass 是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。
实例:
1 | # -*- coding: UTF-8 -*- |
以上实例执行结果:
当前字母 : P
当前字母 : y
当前字母 : t
这是 pass 块
当前字母 : h
当前字母 : o
当前字母 : n
Good bye!
数学函数
math 模块、cmath 模块
Python 中数学运算常用的函数基本都在 math 模块、cmath 模块中。
Python math 模块提供了许多对浮点数的数学运算函数。
Python cmath 模块包含了一些用于复数运算的函数。
cmath 模块的函数跟 math 模块函数基本一致,区别是 cmath 模块运算的是复数,math 模块运算的是数学运算。
查看 math 查看包中的内容:1
2
3
4import math
dir(math)
['__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']
>>>
查看 cmath 查看包中的内容1
2
3
4import cmath
dir(cmath)
['__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atanh', 'cos', 'cosh', 'e', 'exp', 'inf', 'infj', 'isclose', 'isfinite', 'isinf', 'isnan', 'log', 'log10', 'nan', 'nanj', 'phase', 'pi', 'polar', 'rect', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau']
>>>
Python随机数函数
随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。
Python包含以下常用随机数函数:
| 函数 | 描述 |
|---|---|
| choice(seq) | 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 |
| randrange ([start,] stop [,step]) | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数缺省值为1 |
| random() | 随机生成下一个实数,它在[0,1)范围内。 |
| seed([x]) | 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。 |
| shuffle(lst) | 将序列的所有元素随机排序 |
| uniform(x, y) | 随机生成下一个实数,它在[x,y]范围内。 |
Python三角函数
Python包括以下三角函数:
| 函数 | 描述 |
|---|---|
| acos(x) | 返回x的反余弦弧度值。 |
| asin(x) | 返回x的反正弦弧度值。 |
| atan(x) | 返回x的反正切弧度值。 |
| atan2(y, x) | 返回给定的 X 及 Y 坐标值的反正切值。 |
| cos(x) | 返回x的弧度的余弦值。 |
| hypot(x, y) | 返回欧几里德范数 sqrt(xx + yy)。 |
| sin(x) | 返回的x弧度的正弦值。 |
| tan(x) | 返回x弧度的正切值。 |
| degrees(x) | 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0 |
| radians(x) | 将角度转换为弧度 |
Python数学常量
| 常量 | 描述 |
|---|---|
| pi | 数学常量 pi(圆周率,一般以π来表示) |
| e | 数学常量 e,e即自然常数(自然常数)。 |
时间
time
时间间隔是以秒为单位的浮点小数。
每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表示。
- Python 的 time 模块下有很多函数可以转换常见日期格式。如函数time.time()用于获取当前时间戳,
Time 模块
Time 模块包含了以下内置函数,既有时间处理的,也有转换时间格式的.
详情访问:Python 日期和时间
实例
以下实例展示了 time() 函数的使用方法:1
2
3
4
5
6#!/usr/bin/python
import time
print "time.time(): %f " % time.time()
print time.localtime( time.time() )
print time.asctime( time.localtime(time.time()) )
运行结果:
1553931680.6086578
time.struct_time(tm_year=2019, tm_mon=3, tm_mday=30, tm_hour=15, tm_min=41, tm_sec=57, tm_wday=5, tm_yday=89, tm_isdst=0)
Sat Mar 30 15:43:23 2019
日历(Calendar)模块
此模块的函数都是日历相关的,例如打印某月的字符月历。
星期一是默认的每周第一天,星期天是默认的最后一天。
实例
获取某月日历
Calendar模块有很广泛的方法用来处理年历和月历,例如打印某月的月历:
1 | # -*- coding: UTF-8 -*- |
运行结果:
March 2019Mo Tu We Th Fr Sa Su
1 2 3
4 5 6 7 8 9 10
11 12 13 14 15 16 17
18 19 20 21 22 23 24
25 26 27 28 29 30 31
函数
定义一个函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
实例
1 | # -*- coding: UTF-8 -*- |
参数
以下是调用函数时可使用的正式参数类型:
- 必备参数
- 关键字参数
- 默认参数
- 不定长参数
不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,声明时不会命名。基本语法如下:1
2
3
4def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]
加了星号(*)的变量名会存放所有未命名的变量参数。不定长参数实例如下:
####### 实例1
2
3
4
5
6
7
8
9
10
11
12
13
14# -*- coding: UTF-8 -*-
# 可写函数说明
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print "输出: "
print arg1
for var in vartuple:
print var
return;
# 调用printinfo 函数
printinfo( 10 );
printinfo( 70, 60, 50 );
以上实例输出结果:
输出:
10
输出:
70
60
50
匿名函数
python 使用 lambda 来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,…..argn]]:expression
实例
1 | # -*- coding: UTF-8 -*- |
以上实例输出结果:
相加后的值为 : 30
相加后的值为 : 40
Python中的包
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。
简单来说,包就是文件夹,但该文件夹下必须存在 init.py 文件, 该文件的内容可以为空。init.py 用于标识当前文件夹是一个包。
例如:
考虑一个在 package_runoob 目录下的 runoob1.py、runoob2.py、init.py 文件,test.py 为测试调用包的代码,目录结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13test.py
package_runoob
|-- __init__.py
|-- runoob1.py
|-- runoob2.py 源代码如下:
package_runoob/runoob1.py
```python
# -*- coding: UTF-8 -*-
def runoob1():
print "I'm in runoob1"
package_runoob/runoob2.py
1 | # -*- coding: UTF-8 -*- |
现在,在 package_runoob 目录下创建 init.py:
package_runoob/init.py1
2
3
4
5
6
7
# -*- coding: UTF-8 -*-
if __name__ == '__main__':
print '作为主程序运行'
else:
print 'package_runoob 初始化'
然后我们在 package_runoob 同级目录下创建 test.py 来调用 package_runoob 包
test.py1
2
3
4
5
6
7
8# -*- coding: UTF-8 -*-
# 导入 Phone 包
from package_runoob.runoob1 import runoob1
from package_runoob.runoob2 import runoob2
runoob1()
runoob2()
以上实例输出结果:
package_runoob 初始化
I’m in runoob1
I’m in runoob2
文件
读取键盘输入
Python提供了两个内置函数从标准输入读入一行文本,默认的标准输入是键盘。如下:
####### 实例1
2
3
4# -*- coding: UTF-8 -*-
str = raw_input("请输入:")
print "你输入的内容是: ", str
这会产生如下的对应着输入的结果:
请输入:Hello Python!
你输入的内容是: Hello Python!
input函数
input([prompt]) 函数和 raw_input([prompt]) 函数基本类似,但是 input 可以接收一个Python表达式作为输入,并将运算结果返回。
####### 实例1
2
3
4# -*- coding: UTF-8 -*-
str = input("请输入:")
print "你输入的内容是: ", str
这会产生如下的对应着输入的结果:
请输入:[x*5 for x in range(2,10,2)]
你输入的内容是: [10, 20, 30, 40]
打开和关闭文件
Python 提供了必要的函数和方法进行默认情况下的文件基本操作。你可以用 file 对象做大部分的文件操作。
open 函数
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法:
1 | file object = open(file_name [, access_mode][, buffering]) |
各个参数的细节如下:
- file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
- access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
- buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
1 | open(file, mode='r') |
完整的语法格式为:
1 | open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None) |
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener:
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
File对象的属性
一个文件被打开后,你有一个file对象,你可以得到有关该文件的各种信息。
以下是和file对象相关的所有属性的列表:
| 属性 | 描述 |
|---|---|
| file.closed | 返回true如果文件已被关闭,否则返回false。 |
| file.mode | 返回被打开文件的访问模式。 |
| file.name | 返回文件的名称。 |
| file.softspace | 如果用print输出后,必须跟一个空格符,则返回false。否则返回true。 |
如下实例:
1 | # -*- coding: UTF-8 -*- |
以上实例输出结果:
1 | 文件名: foo.txt |
write()方法
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
write()方法不会在字符串的结尾添加换行符(‘\n’):
read()方法
read()方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
语法:
fileObject.read([count])
在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
文件定位
tell()方法告诉你文件内的当前位置, 换句话说,下一次的读写会发生在文件开头这么多字节之后。
seek(offset [,from])方法改变当前文件的位置。Offset变量表示要移动的字节数。From变量指定开始移动字节的参考位置。如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。
重命名和删除文件
Python的os模块提供了帮你执行文件处理操作的方法,比如重命名和删除文件。
要使用这个模块,你必须先导入它,然后才可以调用相关的各种功能。
####### rename()方法:
rename()方法需要两个参数,当前的文件名和新文件名。
语法:
os.rename(current_file_name, new_file_name)
######## 实例
下例将重命名一个已经存在的文件test1.txt。1
2
3
4
5
6# -*- coding: UTF-8 -*-
import os
# 重命名文件test1.txt到test2.txt。
os.rename( "test1.txt", "test2.txt" )
####### remove()方法
你可以用remove()方法删除文件,需要提供要删除的文件名作为参数。
语法:
os.remove(file_name)
######## 实例
下例将删除一个已经存在的文件test2.txt。1
2
3
4
5# -*- coding: UTF-8 -*-
import os
# 删除一个已经存在的文件test2.txt
os.remove("test2.txt")
Python里的目录:
所有文件都包含在各个不同的目录下,不过Python也能轻松处理。os模块有许多方法能帮你创建,删除和更改目录。
目录方法
mkdir()方法
可以使用os模块的mkdir()方法在当前目录下创建新的目录们。你需要提供一个包含了要创建的目录名称的参数。
语法:
os.mkdir(“newdir”)
例子:
chdir()方法
可以用chdir()方法来改变当前的目录。chdir()方法需要的一个参数是你想设成当前目录的目录名称。
语法:
os.chdir(“newdir”)
getcwd()方法:
getcwd()方法显示当前的工作目录。
语法:
os.getcwd()
rmdir()方法
rmdir()方法删除目录,目录名称以参数传递。
在删除这个目录之前,它的所有内容应该先被清除。
语法:
os.rmdir(‘dirname’)
异常处理
try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
语法:
1 | try: |
try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
语法
1 | try: |
实例
以下为单个异常的实例:
1 | # -*- coding: UTF-8 -*- |
以上程序执行结果如下:
1 | $ python test.py |
触发异常
我们可以使用raise语句自己触发异常
raise语法格式如下:
1 | raise [Exception [, args [, traceback]]] |
语句中 Exception 是异常的类型(例如,NameError)参数标准异常中任一种,args 是自已提供的异常参数。
最后一个参数是可选的(在实践中很少使用),如果存在,是跟踪异常对象。
实例
一个异常可以是一个字符串,类或对象。
1 | def functionName( level ): |
面向对象
- getattr(obj, name[, default]) : 访问对象的属性。
- hasattr(obj,name) : 检查是否存在一个属性。
- setattr(obj,name,value) : 设置一个属性。如果属性不存在,会创建一个新属性。
- delattr(obj, name) : 删除属性。
- issubclass() - 布尔函数判断一个类是另一个类的子类或者子孙类,语法:issubclass(sub,sup)
- isinstance(obj, Class) 布尔函数如果obj是Class类的实例对象或者是一个Class子类的实例对象则返回true。
基础重载方法
| 序号 | 方法, 描述 & 简单的调用 |
|---|---|
| 1 | init ( self [,args…] ) 构造函数 简单的调用方法: obj = className(args) |
| 2 | del( self ) 析构方法, 删除一个对象 简单的调用方法 : del obj |
| 3 | repr( self ) 转化为供解释器读取的形式 简单的调用方法 : repr(obj) |
| 4 | str( self ) 用于将值转化为适于人阅读的形式 简单的调用方法 : str(obj) |
| 5 | cmp ( self, x ) 对象比较 简单的调用方法 : cmp(obj, x) |

